WebScraping do WebMotors e visualização dos dados com gráficos interativos em R
Eduardo E. R. Junior - DEST/UFPR
25 de agosto de 2016
Objetivos
Neste trabalho o objetivo é realizar web scraping, ou seja, extração de dados, do site WebMotors com o software R. Esse site contém anúncios de veículos de diversas marcas e modelos e os anúncios trazem informações interessantes para um estudo estatístico, como valor do veículo quilometragem rodada, ano (de fabricação e do modelo), cor etc.
Ainda para apresentar as informações coletadas, este trabalho tem por objetivo expôr novas formas de visualização de dados, explorando a interatividade web. O software R vem crescendo fortemente no ramo de visualizações interativas web, diversos pacotes estão sendo implementados para esta finalidade e aqui iremos utilizar pelo menos três.
Portanto, de forma resumida, os objetivos deste trabalho são:
- Extração de dados da página do WebMotors
- Visualização interativa dos dados coletados
Inspecionando o site
Um primeiro passo para se realizar a extração de dados em páginas web é entender como uma página realmente é. Acredito que todos, seja por acidente ou curiosidade, já viram o código fonte de uma página. Pois bem é neste código fonte que estão as informações que objetivamos.
Na página inicial do WebMotors aparece as opções de veículo para ver os anúncios. Escolheremos a marca Mitsubish e o modelo Pajero Dakar. Com essas informações vamos inspecionar o primeiro anúncio para verificar onde estão as informações dentro do código fonte.
Atualmente os navegadores tem uma funcionalidade de inspeção de página, isso mostra em que parte do código fonte está o elemento inspecionado. Vamos usufruir desta ferramenta para inspecionar o que podemos extrair.
Verificamos que a informação mais relevante do anúncio o preço do veículo, que chamaremos de valor, está dentro de uma tag div de atributos class="price" e itemprop="price" e são essas informações que possibilitam encontrar este valor e capturá-lo com o R.
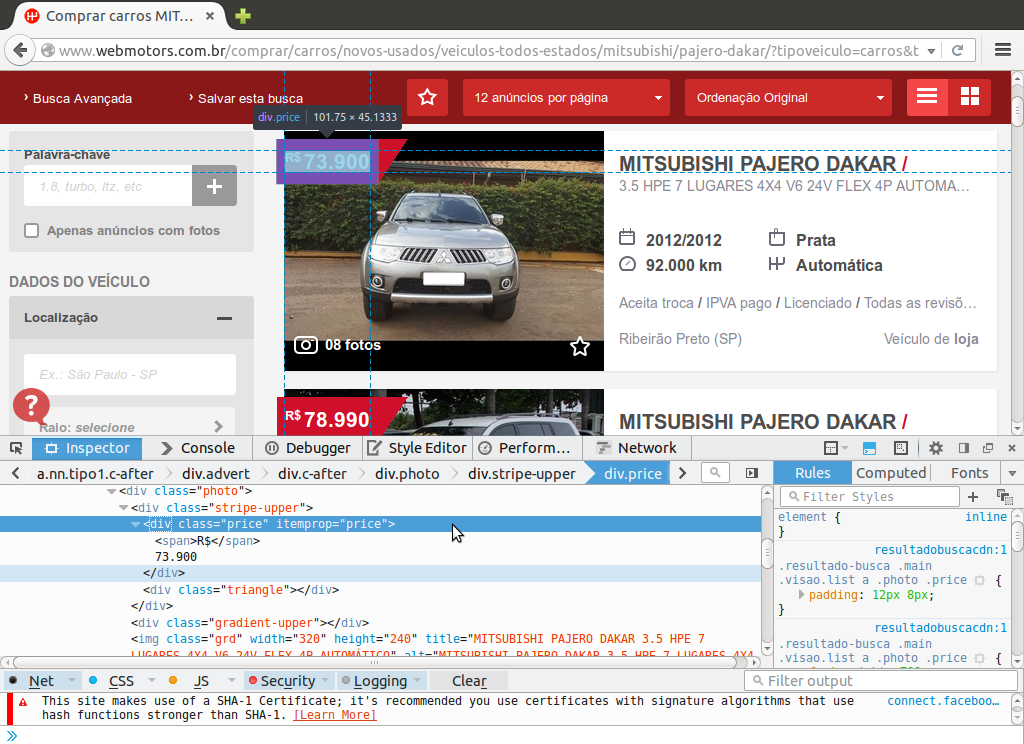
Uma segunda informação contido no anúncio que seria interessante de se coletar é o número de fotos, o nome dado será nfotos. Este valor esta envolto pela tag div que tem o atributo class="stripe-bottom" conforme figura abaixo.
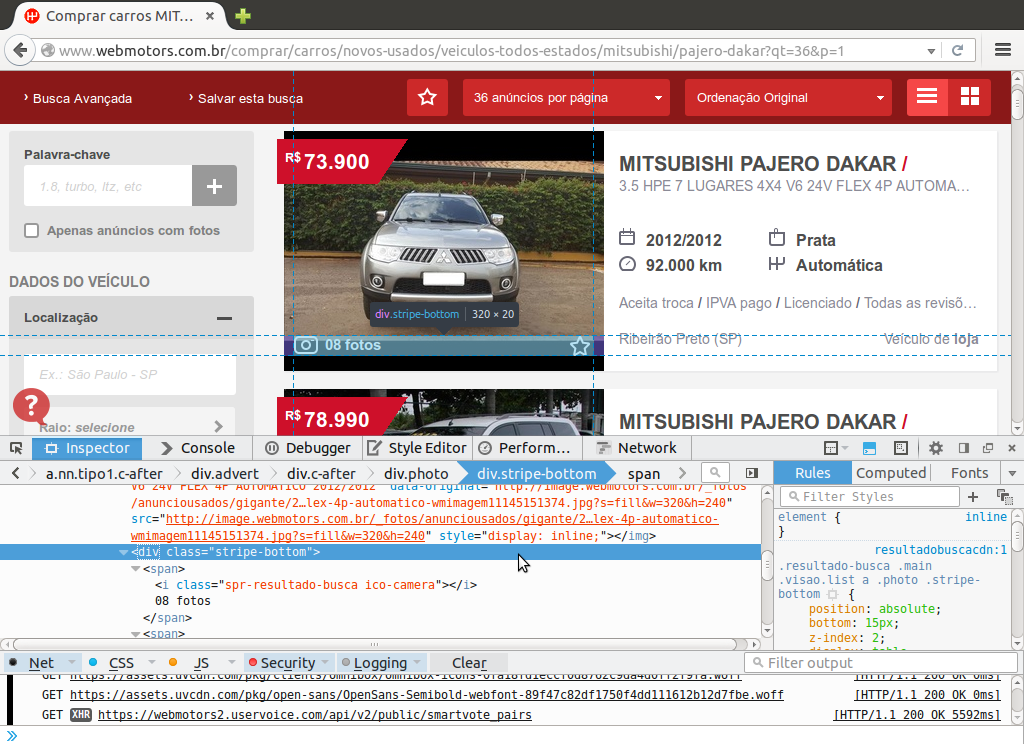
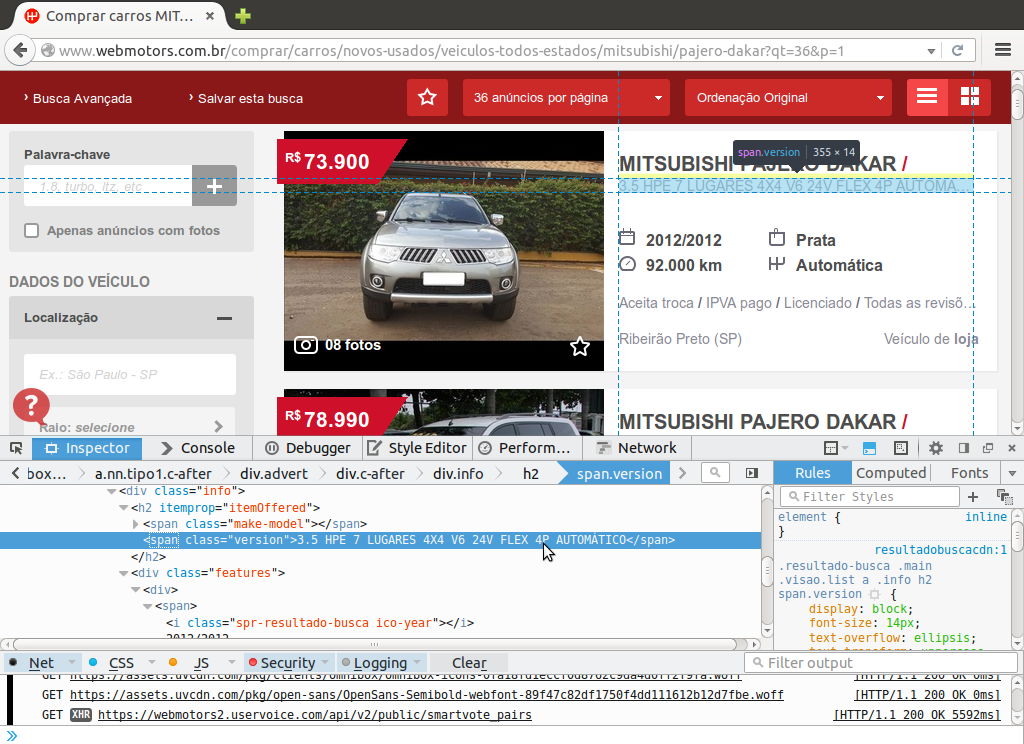
Indo para a porção a direita do anúncio temos algumas informações logo abaixo do título do anúncio, a esta informação será dado o nome de info. Para este dado notamos a presença da tag span de atributo class="version" envolvendo toda a string com as informações da versão do veículo.
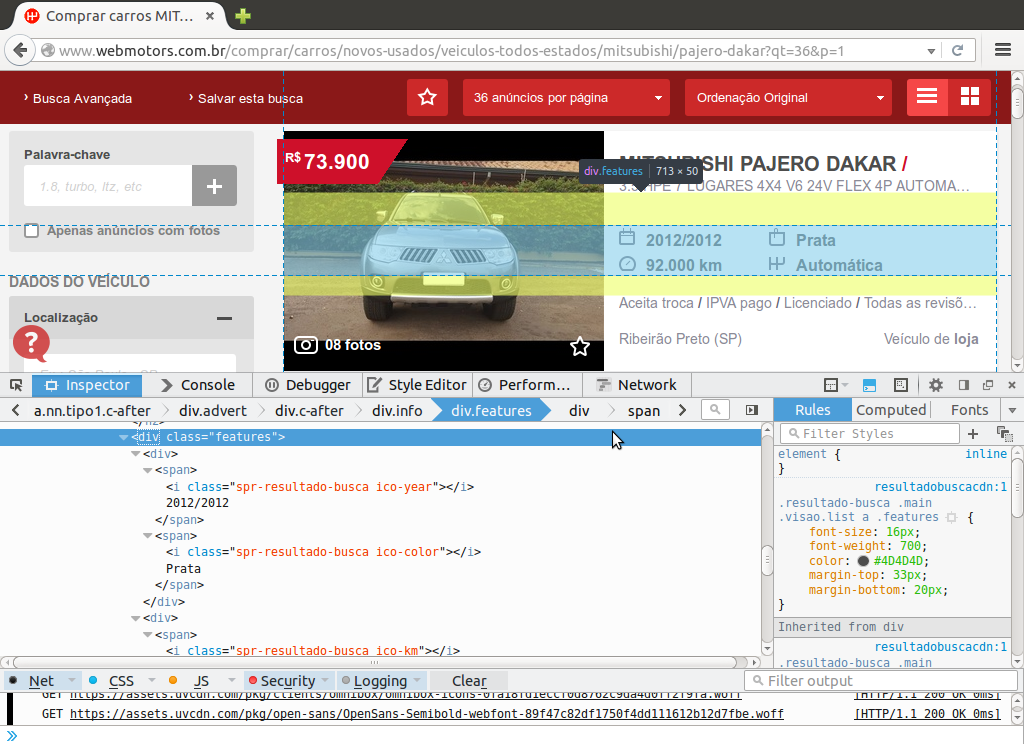
Temos também algumas característica destacadas com ícones que podem ser extraídas e relacionadas com as demais variáveis. Este conjunto de informações será chamado de carac e estão presentes, no código fonte da página, dentro da tag div de class="features" com cada valor envolto pela tag span. Ainda será utilizada a informação da classe da tag i dentro de cada span para verificar a que cada informação obtida se refere, isso para caso ocorra destas aparecer no anúncio em ordem diferente.
Finalmente à direita na parte inferior do anuncio temos as últimas informações que serão coletadas, são elas a cidade do veículo e de qual proprietário ele é. Estas duas informações serão chamadas de info2 no código R e serão coletadas a partir da tag div de class="card-footer" com a localização e proprietário hierarquizados abaixo nas tags span.
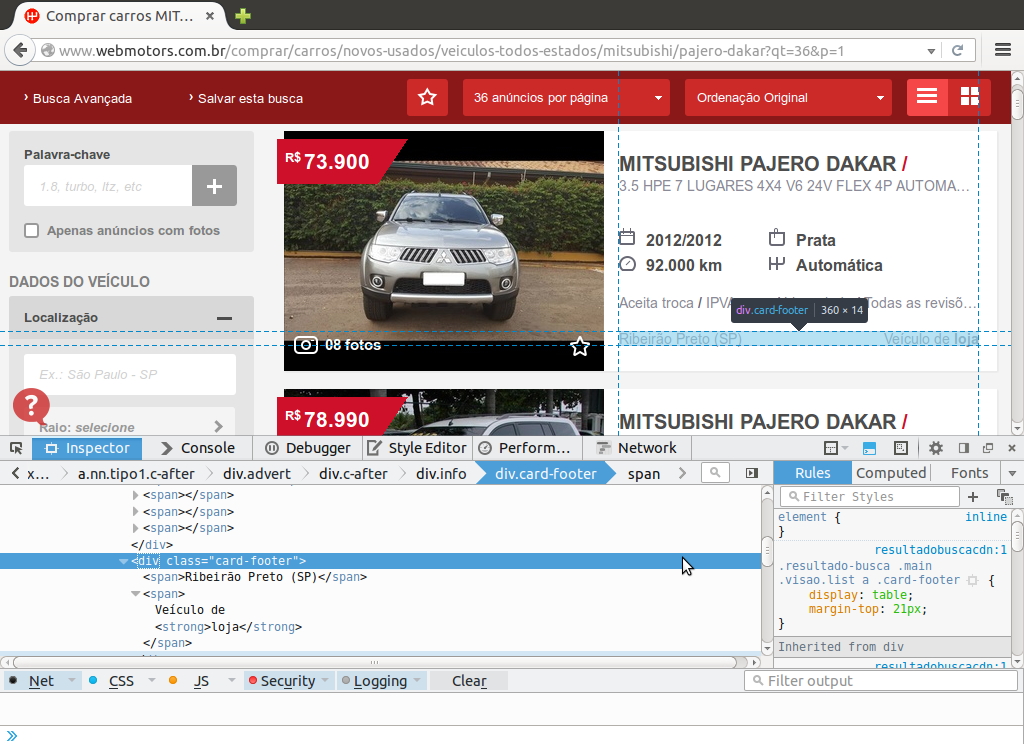
Com isso temos todas as informações necessárias para implementar o código de extração desta primeira página.
Implementando no R
INCLUIR PASSO A PASSO DO WEB SCRAP DA PRIMEIRA PÁGINA
Agora para ler e extrair os dados de todas as páginas que contém anúncio da marca e modelo de veículo escolhido vamos incluir todos os passos de extração em uma função para ser chamada a cada nova página.
getWebMotors <- function(url) {
## Lendo a pagina
pr <- readLines(con = url, warn = FALSE)
## Decodificando-a
h <- htmlTreeParse(file = pr, asText = TRUE,
useInternalNodes = TRUE, encoding = "utf-8")
## Numero de anuncios nesta pagina * O numero de anuncios condiz com
## o número de tags h2 (titulo dos mesmos)
n.anuncios <- length(
xpathApply(h, "//h2[@itemprop=\"itemOffered\"]",fun = xmlValue)
)
##-------------------------------------------
## Valor do veiculo
valor <- getNodeSet(
doc = h,
path = "//div[@class=\"price\"]",
fun = xmlValue
)
valor <- sapply(valor, FUN = function(text) {
gsub(x = gsub(x = text, pattern = "[[:punct:]]",
replace = "", perl = TRUE),
pattern = "^.*R([0-9]+).*", replacement = "\\1")
})
valor <- as.numeric(valor)
##-------------------------------------------
## Numero de fotos
nfotos <- getNodeSet(
doc = h,
path = "//div[@class=\"stripe-bottom\"]//span",
fun = xmlValue
)
nfotos <- nfotos[seq(1, n.anuncios * 2, 2)]
nfotos <- sapply(nfotos, FUN = function(text) {
gsub(x = text, pattern = "^([0-9]+).*", replacement = "\\1")
})
nfotos <- as.integer(nfotos)
##-------------------------------------------
## Informaçoes gerais
info <- getNodeSet(
doc = h,
path = "//span[@class=\"version\"]",
fun = xmlValue
)
info <- sapply(info, FUN = function(text) {
gsub(x = text, "^([0-9]\\.[0-9]) .* (.*)$",
replacement = "\\1")
})
## info <- colsplit(info, split = ";", names = c("cil", "tipo"))
##-------------------------------------------
## Caracteristicas
carac <- getNodeSet(
doc = h,
path ="//div[@class=\"features\"]//span",
fun = xmlValue
)
carac <- unlist(carac)
id <- xpathSApply(
doc = h,
path = "//div[@class=\"features\"]//span//i",
fun = xmlGetAttr, "class")
id <- sapply(as.list(id), FUN = function(text) {
gsub(x = text, "^.*-([a-z]+)$", replacement = "\\1")
})
carac <- unstack(data.frame(carac, id))
carac$km <- as.numeric(
sapply(as.list(carac$km), FUN = function(text) {
if(text == "N/I") NA
else
gsub(x = gsub(x = text, pattern = "[[:punct:]]",
replace = "", perl = TRUE),
pattern = "^([0-9]+) km", replacement = "\\1")
})
)
carac$year <- as.integer(
sapply(as.list(carac$year), FUN = function(text) {
gsub(x = text, "^([0-9]{4})/.*$", replacement = "\\1")
})
)
##-------------------------------------------
## Informações adicionais
info2 <- getNodeSet(
doc = h,
path ="//div[@class=\"card-footer\"]//span",
fun = xmlValue
)
local <- unlist(info2)[seq(1, n.anuncios * 2, 2)]
anuncio <- unlist(info2)[seq(2, n.anuncios * 2, 2)]
local <- sapply(as.list(local), FUN = function(text) {
gsub(x = text, "^(.*) \\(([A-Z]{2})\\)$",
replacement = "\\1;\\2")
})
local <- colsplit(local, split = ";", names = c("cidade", "estado"))
##-------------------------------------------
##-------------------------------------------
## Organizando a saida
da <- list(
valor = valor,
nfotos = nfotos,
cilindradas = info,
## cambio = info$tipo,
cor = carac$color,
km = carac$km,
cambio = carac$shift,
ano = carac$year,
anuncio = as.character(anuncio),
cidade = as.character(local$cidade),
estado = as.character(local$estado)
)
return(da)
}Perceba na função incluímos um passo que não havia na leitura da primeira página, a obtenção do número de anúncios da página. Esta foi uma dificuldade que só foi percebida quando realizado o procedimento completo, pois com exceção da última página todas continham um número de anúncios padrão (12, 24 ou 36) e as contas, para obtenção das posições ímpares e pares das tags, era sempre a mesma, mas para última página os números mudavam e valores NA preenchiam o data.frame.
Agora com a função programada podemos montar o laço iterativo para percorrer todas as páginas e coletar as informações desejadas. Primeiro vamos encontrar quantos veículos anunciados existem e em quantas páginas eles estão dispostos.
##======================================================================
## Extração de dados de todos os veiculos no site webMotors
##-------------------------------------------
## Lendo a primeira página para descobrir o total de veículos
url <- paste0("http://www.webmotors.com.br/comprar/carros/",
"novos-usados/veiculos-todos-estados/mitsubishi/",
"pajero-dakar?qt=36&o=1&p=1")
pr <- readLines(con = url, warn = FALSE)
h <- htmlTreeParse(file = pr, asText = TRUE,
useInternalNodes = TRUE, encoding = "utf-8")
nveiculos <- getNodeSet(
doc = h,
path = "//span[@class=\"size-xbigger\"]",
fun = xmlValue
)
nveiculos <- as.numeric(
gsub(x = as.character(nveiculos),
"^([0-9]+) .*$", replacement = "\\1")
)
nanuncios <- 36 ## Argumento `qt` na url, pode assumir 12, 24 ou 36
npages <- ceiling(nveiculos / nanuncios)Com isso podemos montar nosso data.frame e preenchê-lo com os resultados da função getWebMotors(...). Optou-se pela construção do data.frame geral em branco, pois sistemas do tipo rbind, cbind ou append são caros computacionalmente.
##----------------------------------------------------------------------
## Fazendo o processo de extração iterativamente para as `npages`
## páginas
da <- data.frame(
valor = vector("numeric", nveiculos),
nfotos = vector("integer", nveiculos),
cilindradas = vector("character", nveiculos),
## cambio = info$tipo,
cor = vector("character", nveiculos),
km = vector("numeric", nveiculos),
cambio = vector("character", nveiculos),
ano = vector("integer", nveiculos),
anuncio = vector("character", nveiculos),
cidade = vector("character", nveiculos),
estado = vector("character", nveiculos),
stringsAsFactors = FALSE
)
last <- 0
for(i in 1:npages) {
## Montando as urls
url <- paste0("http://www.webmotors.com.br/comprar/carros/",
"novos-usados/veiculos-todos-estados/mitsubishi/",
"pajero-dakar?qt=", nanuncios, "&o=1&p=", i)
## Extraindo os dados
resul <- getWebMotors(url = url)
## Posições de referencia
pos <- last + 1
last <- nanuncios * i
x <- pos:last
if( i == npages) x <- pos:nveiculos
## Preenchendo o data frame
da$valor[x] <- resul$valor
da$nfotos[x] <- resul$nfotos
da$cilindradas[x] <- resul$cilindradas
da$cor[x] <- resul$cor
da$km[x] <- resul$km
da$cambio[x] <- resul$cambio
da$ano[x] <- resul$ano
da$anuncio[x] <- resul$anuncio
da$cidade[x] <- resul$cidade
da$estado[x] <- resul$estado
}Uma dificuldade do processo de web scraping é que as páginas web geralmente são dinâmicas, não no sentido computacional (JavaScript, Ajax etc.), mas no sentido de que há anúncios sendo adicionados e excluídos a todo momento. No início deste trabalho foram consultados r nrow(read.table("pajero-dakar.csv", header = TRUE, sep = ";")) anúncios, hoje são nrow(da).
Visualizando os dados
Finalmente com os dados extraídos podemos ir para a visualização dos dados obtidos. Podemos partir para as visualizações. E neste trabalho vamos explorar recursos interativos do R para tal tarefa.
Várias bibliotecas em R permitem a elaboração de gráficos interativos aqui optamos por utilizar recursos de três delas: rCharts, googleVis e plotly.
Embora que já realizada uma higienização dos dados no momento da coleta, porém algumas mudanças foram feitas posteriormente e são elas:
- Padronizar as cores dos veículos
cordeixando-as todas minúsculas - Para melhor visualização (principalmente devido a escala), trabalharemos com o logaritmo de base 10 do preço dos veículos
valor(\(\log_{10}(\text{`valor`})\)) - Por uma limitação de interatividade (não permite caracteres especiais em função javascript para colorir em
rPlot(...))
##-------------------------------------------
## Padronizando o conjunto de dados
da$lvalor <- log10(da$valor)
da$cor <- tolower(da$cor)
da$motor <- as.factor(paste0("v", da$cilindradas * 1000))A partir destas mudanças temos o resumo das variáveis numéricas abaixo:
## valor nfotos cilindradas km
## Min. : 73200 Min. : 0.00 Min. :3.200 Min. : 0
## 1st Qu.: 94768 1st Qu.: 5.00 1st Qu.:3.200 1st Qu.: 23000
## Median :105000 Median : 7.00 Median :3.200 Median : 51272
## Mean :113350 Mean : 6.26 Mean :3.266 Mean : 54674
## 3rd Qu.:125225 3rd Qu.: 8.00 3rd Qu.:3.200 3rd Qu.: 84796
## Max. :240000 Max. :14.00 Max. :3.500 Max. :188000
## NA's :54
## ano lvalor
## Min. :2009 Min. :4.865
## 1st Qu.:2011 1st Qu.:4.977
## Median :2012 Median :5.021
## Mean :2012 Mean :5.043
## 3rd Qu.:2013 3rd Qu.:5.098
## Max. :2016 Max. :5.380
## E para as não numéricas:
## cor cambio
## Length:668 Automática :616
## Class :character Automática Sequencial: 19
## Mode :character Manual : 33
##
##
##
##
## anuncio cidade estado
## Veículo de concessionária:184 São Paulo :127 SP :304
## Veículo de loja :349 Rio de Janeiro: 45 RJ : 67
## Veículo de particular :135 Belo Horizonte: 23 MG : 64
## Curitiba : 21 PR : 41
## Jundiaí : 21 SC : 29
## Goiânia : 18 RS : 25
## (Other) :413 (Other):138
## motor
## v3200:522
## v3500:146
##
##
##
##
## Com isso já podemos imaginar alguns gráficos a serem elaborados para melhor visualização destas 666 variáveis.
Gráficos univariados
Para verificar a disposição dos anúncios para cada variável extraído iremos elaboras gráficos univariados. O primeiro deles, logo abaixo, exibe o número de veículos para cada cor encontrada nos anúncios.
Frequência de anúncios pelas cores dos veículos
Percebemos que há uma predominância das cores branco, preto e prata. Portanto reagrupamos as cores para continuidade da análise.
##-------------------------------------------
## Recategorizando as cores
da$cor[!(da$cor %in% c("branco", "preto", "prata"))] <- "vários"Frequências pelos anos de fabricação
Neste gráfico temos a disposição do ano de fabricação dos veículos e notamos que há uma disposição simétrica em torno de 2012 da frequência de veículos em cada ano. Além disso conseguimos identificar um anúncio equivocado, pois temos uma obervação para o ano de fabricação 2016 (equívoco ou temos um carro do futuro a venda?). Supomos o ano de fabricação deste veículo como 2015 no decorrer do estudo.
##-------------------------------------------
## Corrigindo anuncio equivocado
da[da$ano == 2016, ]$ano <- 2015Frequência de anúncios pelo Estado de origem
Agora observando a frequência de anúncios por estado, temos a predominância de São Paulo com da2[da2$estados == "SP", ]$anúncios e com maiores contagens para as regiões Sudeste e Sul.
Densidade do preço dos veículos
Para a variável de maior interesse nesse estudo, o preço dos veículos, temos no gráfico acima, a densidade empírica estimada do logaritmo de base 10 e notamos a assimetria da distribuição (à direita) com a moda 4.99, a mediana 5.02 e a média 5.04.
Gráficos multivariados
Nesta seção estudaremos as relações entre as variáveis do estudo.
Preço vs km por anúncio
Frequência de anúncios por anunciante e cor
Preço vs número de fotos do anúncios
Preço médio por estado
Dispersão considerando todas as variáveis
Frequência dos anúncios por preço, anunciante e tipo de câmbio
Referências
- Web Scraping Corrida São Silveste Tutorial de Web Scraping pelo Blog do LEG
- Web Scraping em cifras de música Tutorial de Web Scraping pelo Blog do LEG
- rCharts.io Página do pacote rCharts
- NVD3 with rCharts Post com exemplos NVD3 do rCharts (função
nPlot(...)) - GoogleCharts Galeria de gráficos do Google
- googleVis vignettes Exemplos do pacote googleVis no CRAN
- Plotly Página principal do Plotly